Selecting the Number and Labels of Topics in Topic Modeling: A Tutorial
Sara J. Weston, Ian Shryock, Ryan Light, Phillip A. Fisher
*Advances in Methods and Practices in Psychological Science*
Abstract
Topic modeling is a type of text analysis that identifies clusters of co-occurring words, or latent topics. A challenging step of topic modeling is determining the number of topics to extract. This tutorial describes tools researchers can use to identify the number and labels of topics in topic modeling. First, we outline the procedure for narrowing down a large range of models to a select number of candidate models. This procedure involves comparing the large set on fit metrics, including exclusivity, residuals, variational lower bound, and semantic coherence. Next, we describe the comparison of a small number of models using project goals as a guide and information about topic representative and solution congruence. Finally, we describe tools for labeling topics, including frequent and exclusive words, key examples, and correlations among topics.
Introduction
Topic modeling is a type of text analysis that identifies clusters of co-occurring words, or latent topics. Topics can map the semantic structure of a corpus and quantify the degree to which a theme is present in a specific text. For psychological scientists, it can supplement or replace human coding, scale to large datasets, and uncover broad subject-matter-based themes.
This tutorial focuses on two key aspects of topic modeling:
- Selecting the number of topics to estimate.
- Labeling the topics.
We assume readers are familiar with basic topic modeling steps and demonstrate using the structural topic model (STM), which can incorporate covariates into both prevalence and content, making it especially useful for psychological research.
Software
All analyses were conducted in R (Version 4.1.3), using primarily the stm and tidytext packages, with tidyverse for data cleaning and visualization.
Data Description
We used data from the Rapid Assessment of Pandemic Impact on Development–Early Childhood (RAPID-EC) project:
- Nationally representative parents of children aged 5 and younger.
- Open-ended question: “How do you feel about the COVID-19 vaccine in terms of its safety and effectiveness, and what are your plans in terms of whether or not to get it?”
- Administered biweekly between March–December 2021.
- 3,331 parents; 6,516 total responses.
Data and code are available at: https://osf.io/4nt8x.
Tutorial Overview
1. Data Cleaning
- Remove numbers, special characters, stop words, words with fewer than 20 uses.
- Use
textProcessor()andprepDocuments()instm.
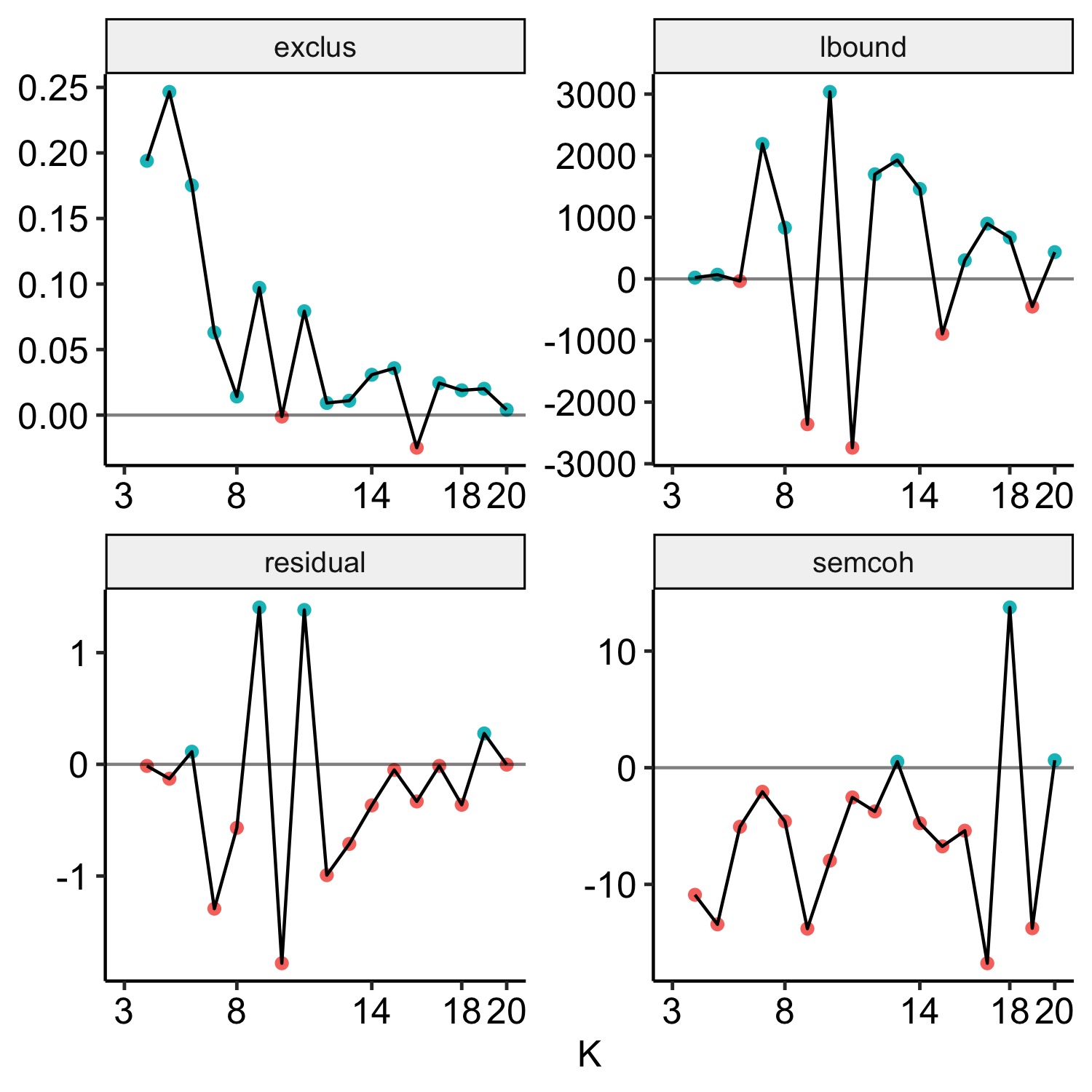
2. Narrowing Candidate Models
- Fit multiple solutions using
searchK()and compare:- Exclusivity
- Residuals
- Variational lower bound
- Semantic coherence
- Example candidate solutions: 8, 14, and 18 topics.
3. Evaluating Models
- Consider project goals.
- Assess topic prevalence using the
thetamatrix. - Compare solution congruence using the
betamatrix.
4. Labeling Topics
- Use frequent and exclusive words (
labelTopics()). - Extract key examples (
findThoughts()). - Examine topic correlations (
topicCorr()).
Key Findings
- No single correct number of topics; choice depends on goals, data, and interpretability.
- Topic labeling can reveal robust cross-solution themes, rare but important topics, and non-informative topics.
- Provided practical R code for all steps.
Citation
Weston, S. J., Shryock, I., Light, R., & Fisher, P. A. (2023). Selecting the number and labels of topics in topic modeling: A tutorial. Advances in Methods and Practices in Psychological Science, 6(2), 1–13. https://doi.org/10.1177/25152459231160105