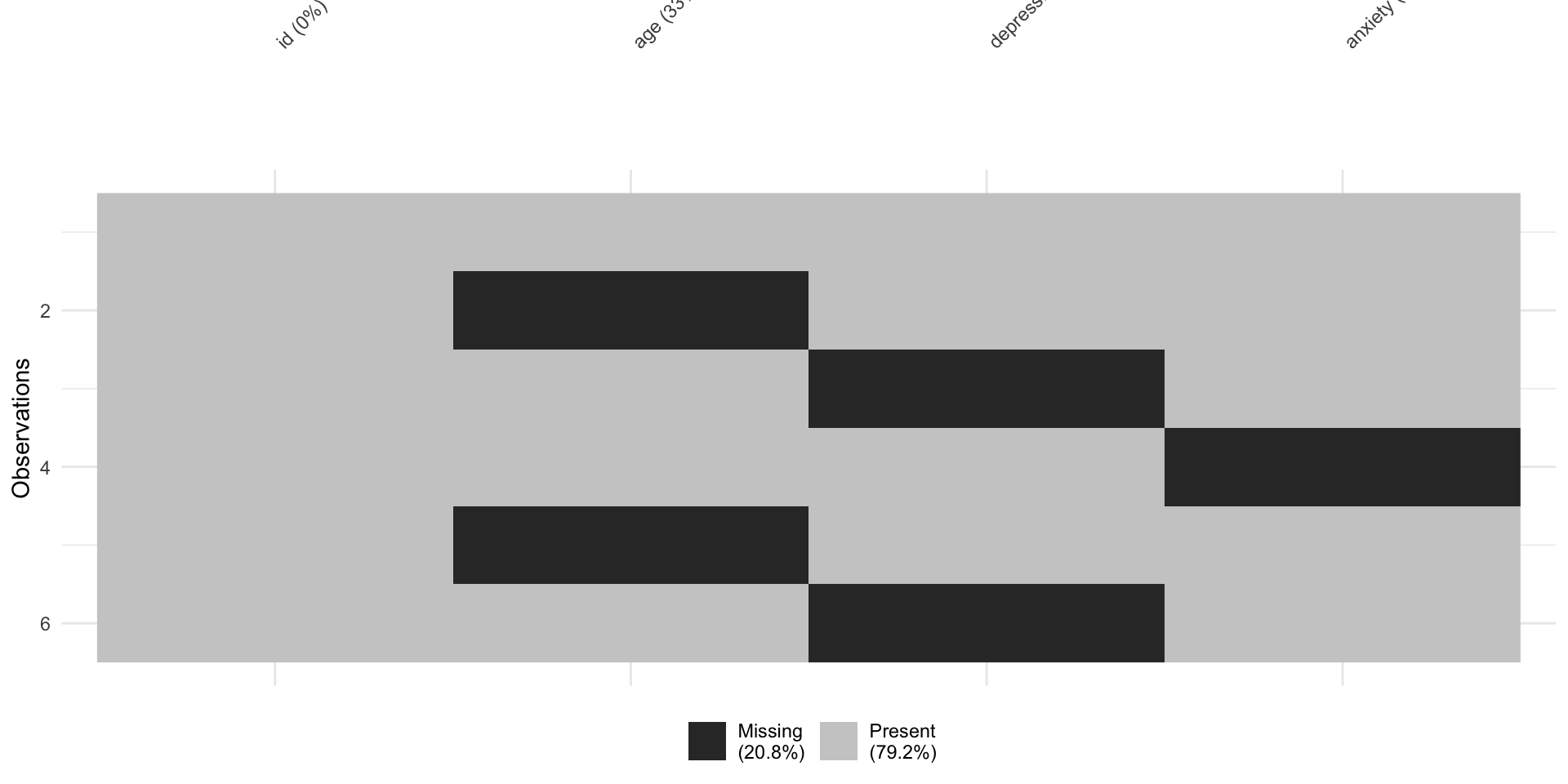
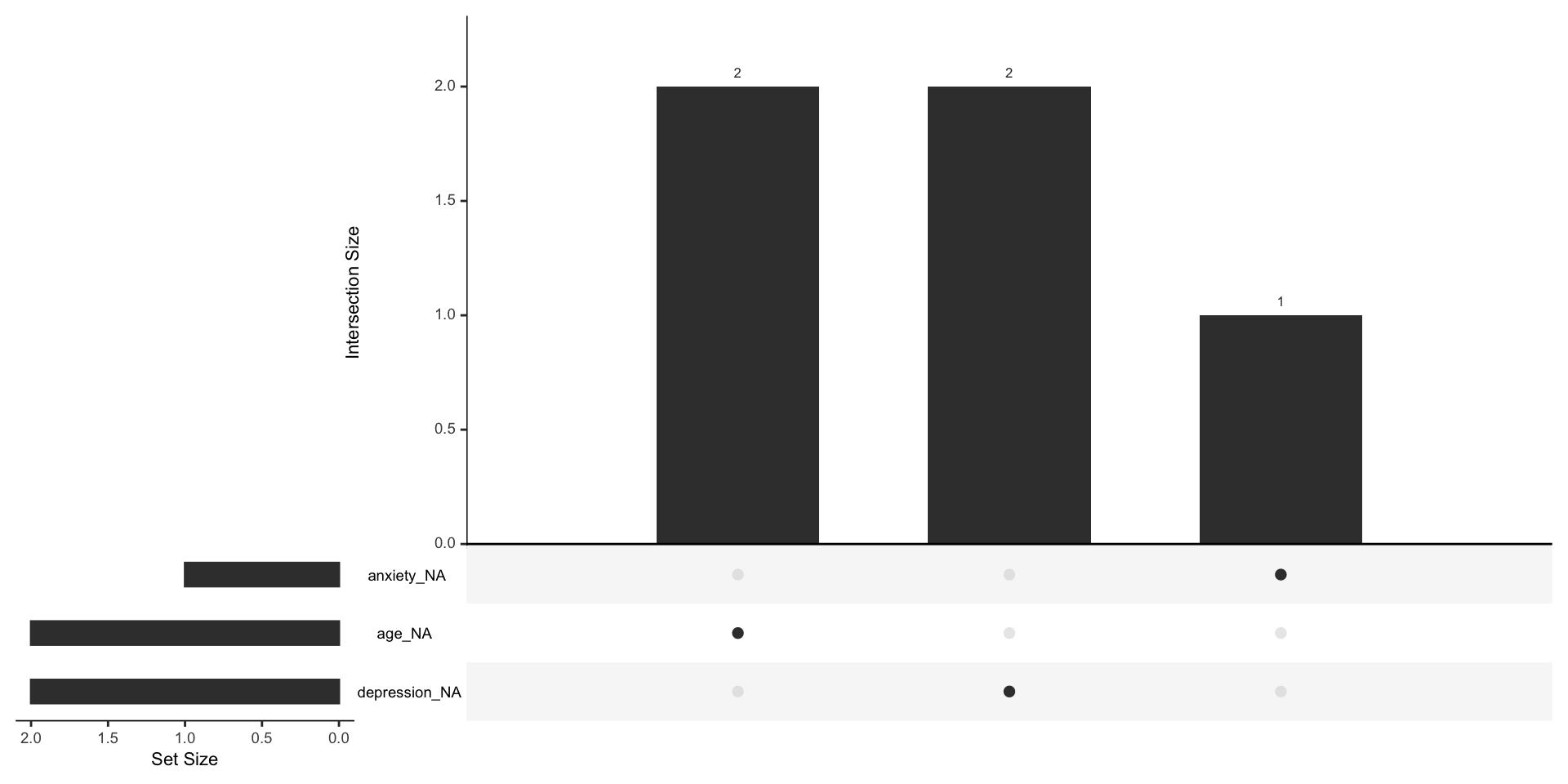
survey <- tibble(
participant = 1:5,
age = c(25, NA, 30, 22, NA),
depression = c(12, 18, NA, 10, 15)
)
survey# A tibble: 5 × 3
participant age depression
<int> <dbl> <dbl>
1 1 25 12
2 2 NA 18
3 3 30 NA
4 4 22 10
5 5 NA 15