| id | gender |
|---|---|
| 1 | Male |
| 2 | male |
| 3 | M |
| 4 | MALE |
| 5 | Female |
| 6 | female |
| 7 | F |
Strings & Factors
PSY 410: Data Science for Psychology
Dr. Sara Weston
2026-05-06
The Power Play
Something new in the team challenge
The top 2 teams on the scoreboard right now get a one-time strategic choice:
Option A — Boost: Add +3 points to your own team’s total
Option B — Sabotage: Remove 2 points from each of two other teams of your choice
Choices are final. First place picks first.
Strings: The basics
How many genders are in this dataset?
How many genders are in this dataset?
R says 7. You meant 2.
The problem is inconsistent text — different cases, abbreviations, trailing spaces. Today we learn to fix that.
What are strings?
Strings are text data — anything in quotes:
The stringr package (part of tidyverse) gives you tools for working with strings. All stringr functions start with str_.
Creating and combining strings
[1] "JaneDoe"[1] "Jane Doe"String length
Changing case
[1] "male" "female" "male" "female" "male" [1] "MALE" "FEMALE" "MALE" "FEMALE" "MALE" [1] "Male" "Female" "Male" "Female" "Male" Essential for cleaning demographic data!
Trimming whitespace
Survey data often has extra spaces:
Psychology example: Cleaning demographics
Detecting patterns
str_detect() checks if a pattern is present:
Case-insensitive detection
Patterns are case-sensitive by default:
Replacing text
Multiple replacements
diagnosis <- c("MDD", "GAD", "MDD", "OCD", "GAD")
# Replace multiple patterns at once
str_replace_all(diagnosis, c(
"MDD" = "Major Depressive Disorder",
"GAD" = "Generalized Anxiety Disorder",
"OCD" = "Obsessive-Compulsive Disorder"
))[1] "Major Depressive Disorder" "Generalized Anxiety Disorder"
[3] "Major Depressive Disorder" "Obsessive-Compulsive Disorder"
[5] "Generalized Anxiety Disorder" Extracting parts of strings
When you need more: Regular expressions
Regular expressions (regex) are powerful pattern matching tools.
Examples:
\\dmatches digits\\smatches whitespace.matches any character+means “one or more”*means “zero or more”
Note
Regex is powerful but complex. For this course, stick to simple patterns. When you need more, check R4DS Ch 14 or regex101.com.
Pair coding break
Your turn: Clean text data
You have messy survey responses:
- Clean
genderto lowercase with no extra spaces - Clean
commentto title case with no extra spaces - Create a logical column
is_negativethat is TRUE if the comment contains “long” or “confusing” (case-insensitive) - Filter to only negative comments
Time: 10 minutes
Factors
What are factors?
Factors are R’s way of representing categorical data with a fixed set of possible values.
Notice the Levels line — those are the possible categories.
Why use factors?
- Memory efficient — R stores categories once, not repeatedly
- Prevent typos — Can’t accidentally add invalid categories
- Control order — Specify the order for plots and tables
- Model requirements — Many statistical models require factors
Creating factors
Order matters!
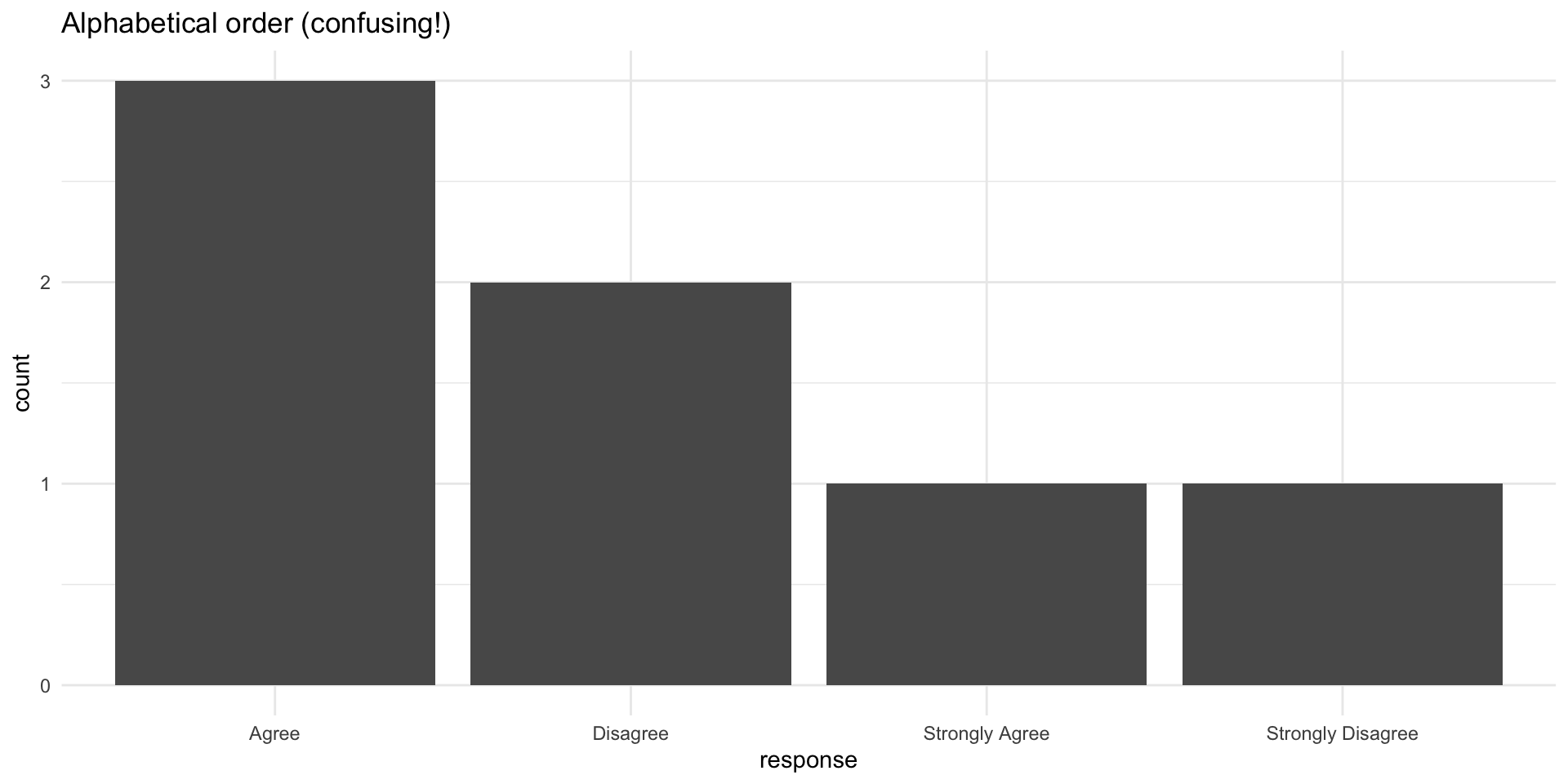
Why order matters: Example
Why order matters: Example
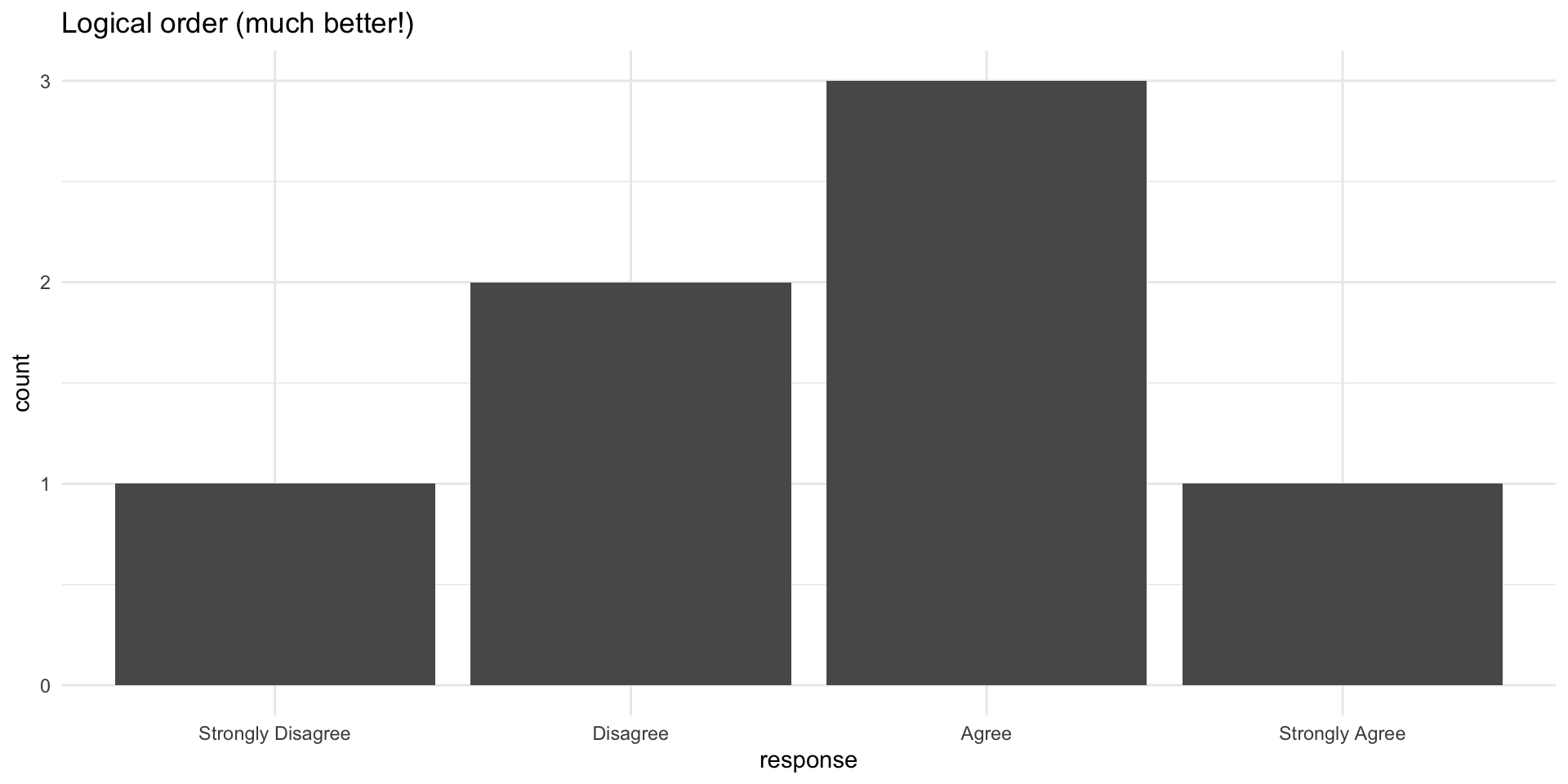
Fixed with factor ordering
Fixed with factor ordering
Forcats: Factor tools
The forcats package (part of tidyverse) provides functions for working with factors.
All forcats functions start with fct_.
Key functions:
fct_relevel()— manually reorder levelsfct_reorder()— reorder by another variablefct_infreq()— order by frequencyfct_recode()— rename levelsfct_collapse()— combine levels
fct_relevel(): Manual reordering
[1] High School Bachelor's Master's High School
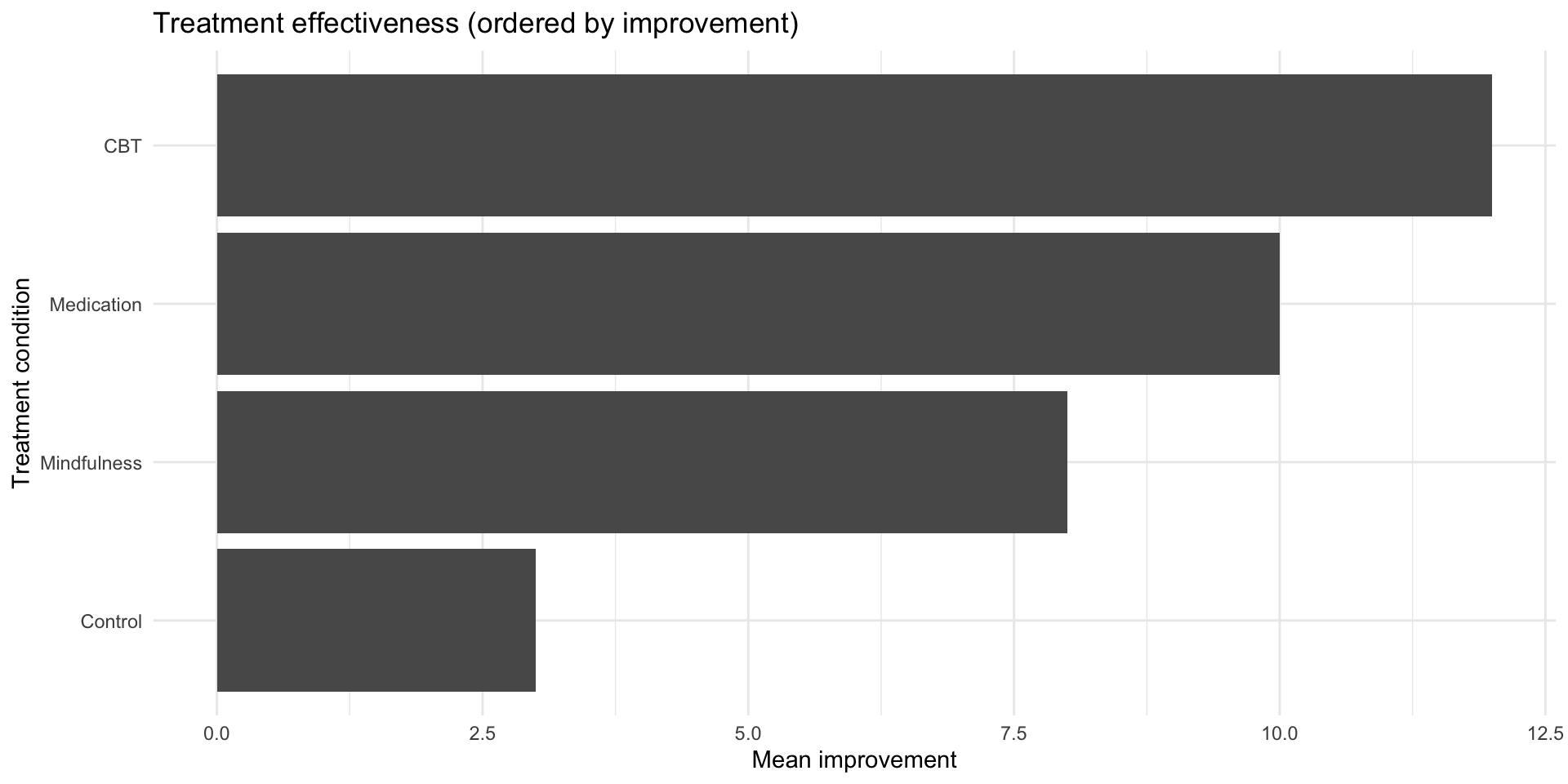
Levels: Bachelor's High School Master'sfct_reorder(): Order by another variable
Extremely useful for plots!
fct_reorder() in action
fct_reorder() in action
fct_infreq(): Order by frequency
fct_infreq() in plots
fct_infreq() in plots
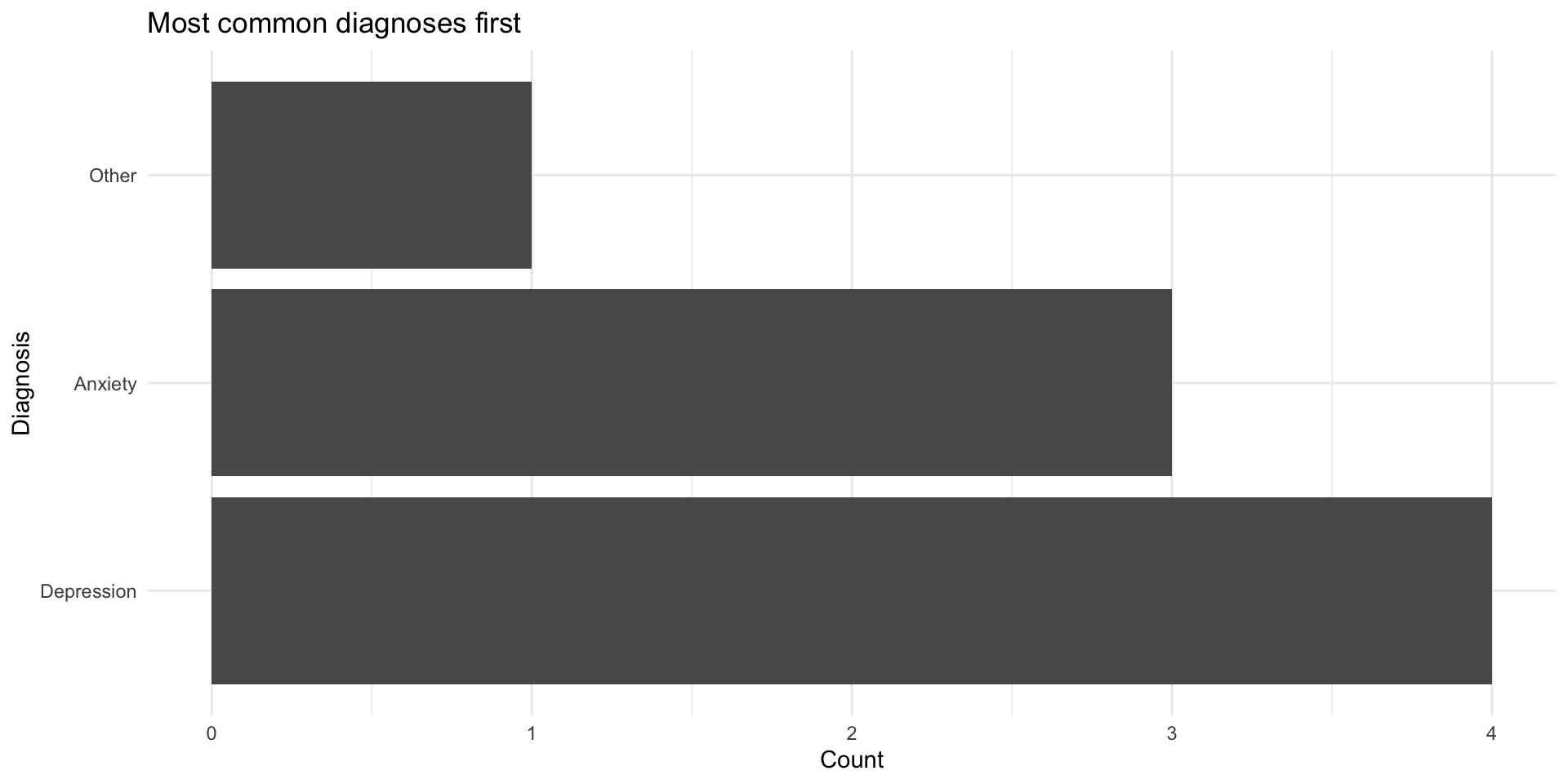
fct_recode(): Rename levels
fct_collapse(): Combine levels
Useful for grouping rare categories:
diagnosis <- factor(c("MDD", "GAD", "OCD", "PTSD", "Panic Disorder",
"MDD", "GAD", "Social Anxiety"))
fct_collapse(diagnosis,
Depression = "MDD",
Anxiety = c("GAD", "OCD", "PTSD", "Panic Disorder", "Social Anxiety")
)[1] Depression Anxiety Anxiety Anxiety Anxiety Depression Anxiety
[8] Anxiety
Levels: Anxiety DepressionPsychology example: Recoding demographics
demo_data <- tibble(
age_group = c("18-25", "26-35", "18-25", "36-45", "26-35", "46+"),
education = c("HS", "BA", "BA", "MA", "HS", "PhD")
)
demo_data |>
mutate(
# Order age groups logically
age_group = factor(age_group, levels = c("18-25", "26-35", "36-45", "46+")),
# Expand education codes
education = fct_recode(factor(education),
"High School" = "HS",
"Bachelor's" = "BA",
"Master's" = "MA",
"Doctorate" = "PhD"
)
)# A tibble: 6 × 2
age_group education
<fct> <fct>
1 18-25 High School
2 26-35 Bachelor's
3 18-25 Bachelor's
4 36-45 Master's
5 26-35 High School
6 46+ Doctorate Dropping unused levels
After filtering, factors keep old levels:
Common factor issues
Problem 1: Factors created from numbers
Common factor issues
Problem 2: Factors behave differently than strings
colors <- factor(c("red", "blue"))
# Can't just add new values
colors[3] <- "green" # This creates NA!
colors[1] red blue <NA>
Levels: blue redSolution: Convert to character first, or use fct_expand() to add levels.
Light text analysis
What did you say about data?
On the class survey, you described your relationship with data in 1–2 words. Let’s see what you said.
# A tibble: 10 × 1
data_words
<chr>
1 natoque imperdiet ligula commodo! convallis accusamus tincidunt luctus viver…
2 imperdiet. natoque morbi mattis! fringilla pede lectus tempor mi dignissim i…
3 morbi et pede luctus at. sit wisi fermentum quis metus dui.
4 fermentum cursus leo placerat erat sapien aliquam nunc cursus sed nec ipsum …
5 sit eu gravida fringilla vulputate rutrum, sem nulla at platea. iaculis ut. …
6 suspendisse tempus. dui. sapien mi quis dui integer montes sit eleifend? imp…
7 suscipit temporibus mi eros integer blandit vestibulum. dui ridiculus sodale…
8 morbi dapibus ullamcorper aliquam vestibulum molestie magnis ab malesuada co…
9 morbi sed rutrum, sagittis. pede gravida euismod? lectus nonummy convallis p…
10 tincidunt posuere nec nec fusce vestibulum! sagittis? venenatis nulla nec lo…Tokenizing text with tidytext
unnest_tokens() splits text into individual words:
# A tibble: 615 × 1
word
<chr>
1 natoque
2 imperdiet
3 ligula
4 commodo
5 convallis
6 accusamus
7 tincidunt
8 luctus
9 viverra
10 scelerisque
# ℹ 605 more rowsEach row is now a single word.
What words came up most?
words |>
anti_join(stop_words, by = "word") |>
count(word, sort = TRUE) |>
slice_head(n = 10) |>
mutate(word = fct_reorder(word, n)) |>
ggplot(aes(x = n, y = word)) +
geom_col(fill = "steelblue") +
labs(
title = "How Our Class Describes Their Relationship with Data",
x = "Count",
y = NULL
) +
theme_minimal(base_size = 14)What words came up most?
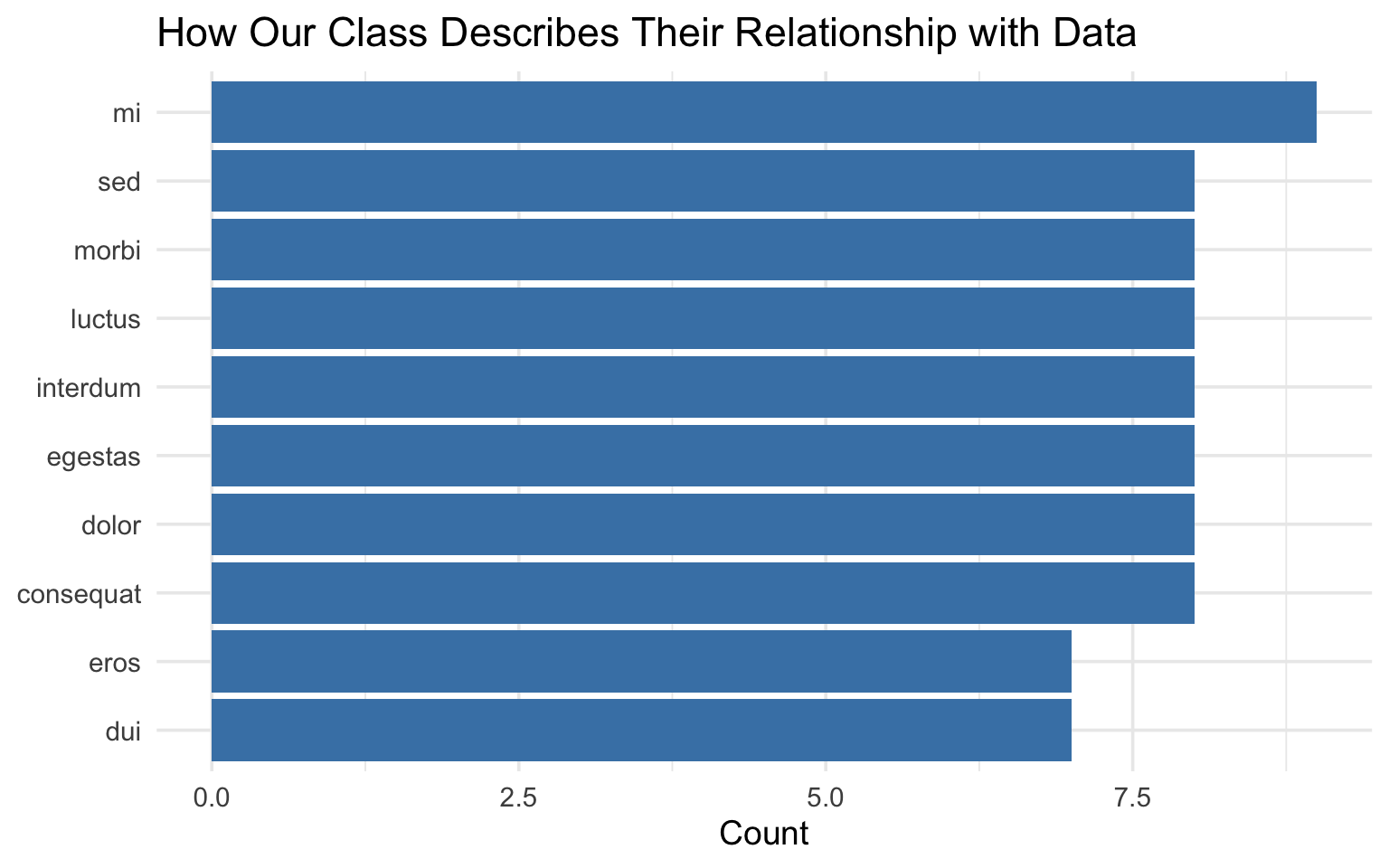
End-of-deck exercise
Practice: Clean and visualize survey data
You have messy Likert scale data:
- Clean the
responsevariable to title case - Convert
responseto a factor with logical ordering - Create a bar chart showing response counts for each question
- Use
facet_wrap()to make separate panels for each question - Bonus: Use
fct_infreq()to order responses by overall frequency
Wrapping up
String functions cheat sheet
| Function | Purpose |
|---|---|
str_c() |
Combine strings |
str_length() |
Get string length |
str_to_lower(), str_to_upper() |
Change case |
str_trim(), str_squish() |
Remove whitespace |
str_detect() |
Find pattern |
str_replace(), str_replace_all() |
Replace pattern |
str_sub() |
Extract substring |
Factor functions cheat sheet
| Function | Purpose |
|---|---|
factor() |
Create a factor |
fct_relevel() |
Manually reorder levels |
fct_reorder() |
Order by another variable |
fct_infreq() |
Order by frequency |
fct_recode() |
Rename levels |
fct_collapse() |
Combine levels |
fct_drop() |
Remove unused levels |
Key takeaways
- Strings are text — use
stringr::str_*()functions to manipulate - Always clean string data — case, whitespace, typos
- Factors are categorical data with fixed levels
- Factor order matters for plots and tables
- Use forcats (
fct_*()) to manipulate factors - Order factors logically — not alphabetically
- When in doubt, check the data type with
class()orglimpse()
Before next class
📖 Read:
- R4DS Ch 19: Joins
✅ Do:
- Submit Assignment 6
- Check your final project data for string/factor issues
- Practice cleaning demographic variables
The one thing to remember
Messy categories turn into messy results. str_to_lower() and factor() are your first line of defense.
See you Monday for joins!
PSY 410 | Session 12