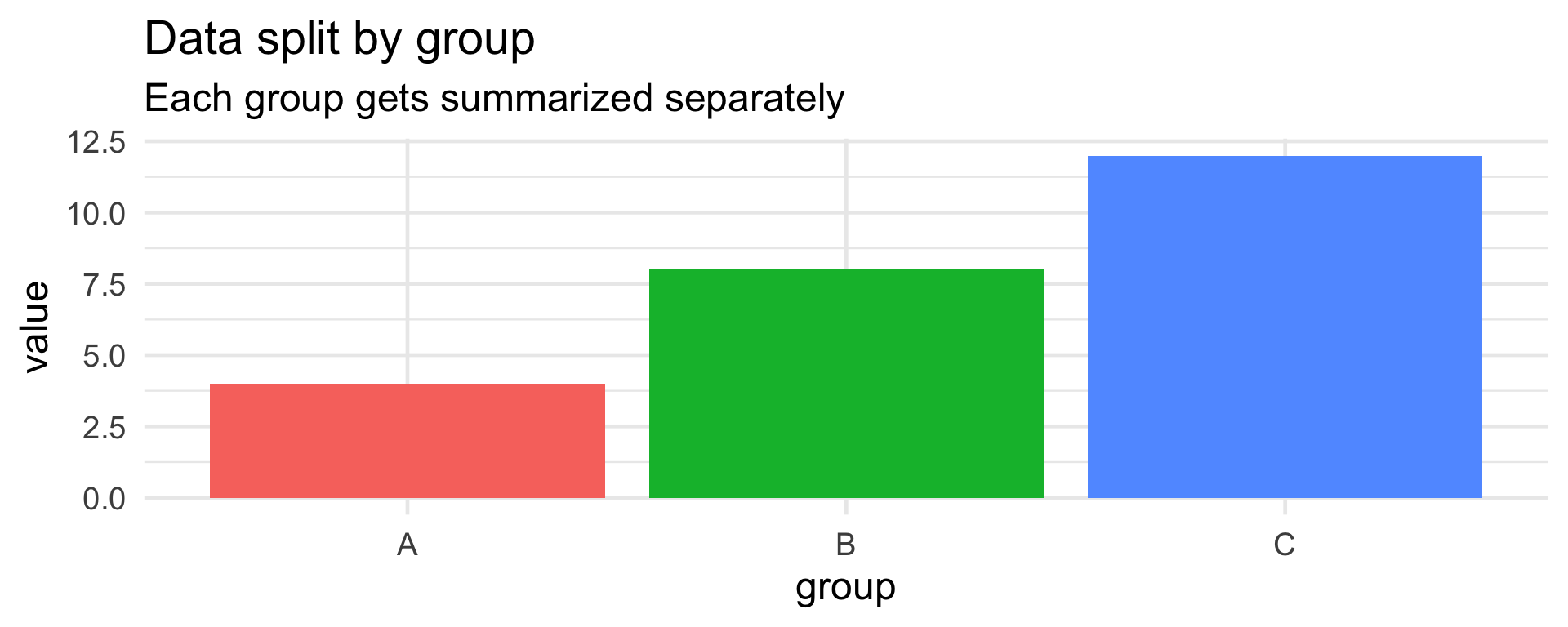
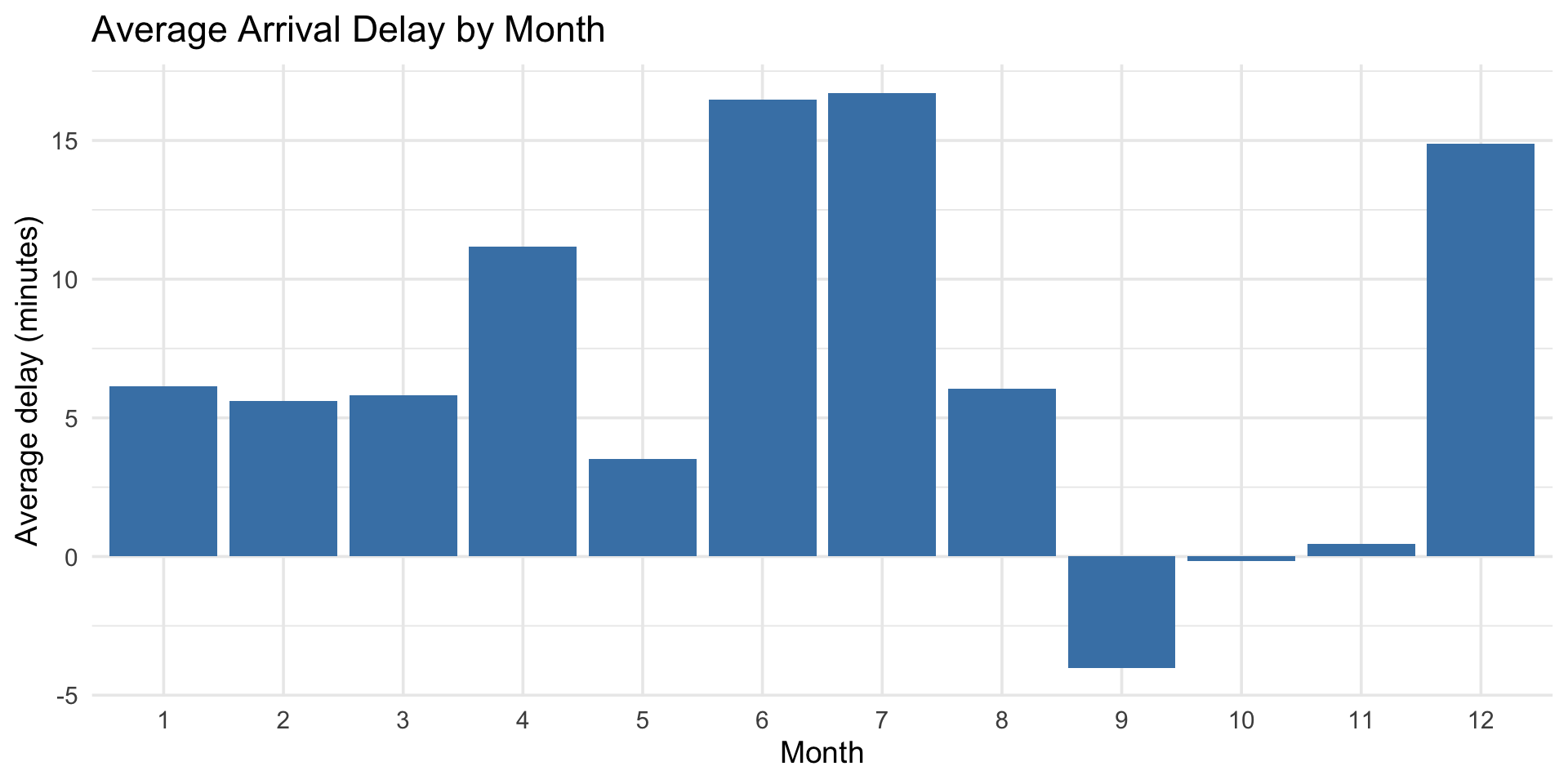
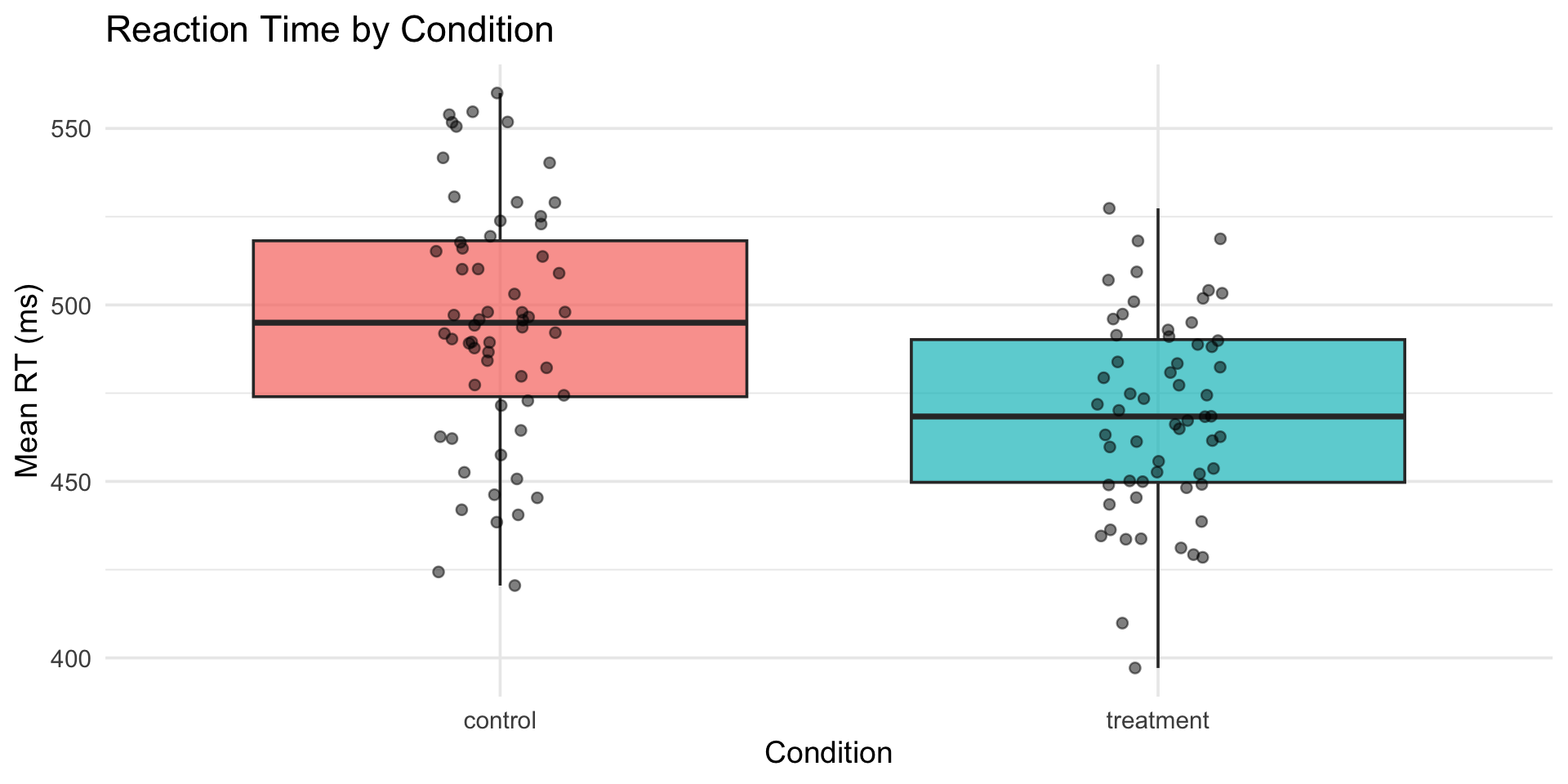
flights |>
summarize(
avg_delay = mean(dep_delay, na.rm = TRUE),
max_delay = max(dep_delay, na.rm = TRUE),
n_flights = n()
)# A tibble: 1 × 3
avg_delay max_delay n_flights
<dbl> <dbl> <int>
1 12.6 1301 336776